Strawman Overview¶
This overview was distilled from Strawman: A Batch In Situ Visualization and Analysis Infrastructure for Multi-Physics Simulation Codes . This paper was presented at the ISAV 2015 Workshop, held in conjunction with SC 15, on November 16th 2015 in Austin, TX, USA.
Requirements¶
To guide the development of Strawman, we focused on a set of important in situ visualization and analysis requirements extracted from our interactions and experiences with several simulation code teams. Here are Strawman’s requirements broken out into three broader categories:
- Support a diverse set of simulations on many-core architectures.
- Support execution on many-core architectures
- Support usage within a batch environment (i.e.,no simulation user involvement once the simulation has begun running).
- Support the four most common languages used by simulation code teams: C, C++, Python, and Fortran.
- Support for multiple data models, including uniform, rectilinear, and unstructured grids.
- Provide a streamlined interface to improve usability.
- Provide straight forward data ownership semantics between simulation routines and visualization and analysis routines
- Provide a low-barrier to entry with respect to developer time for integration.
- Ease-of-use in terms of directing visualization and analysis actions to occur during runtime.
- Ease-of-use in terms of consuming visualization results, including delivery mechanisms both for images on a file system and for streaming to a web browser.
- Minimize the resource impacts on host simulations.
- Synchronous in situ processing, meaning that visualization and analysis routines can directly access the memory of a simulation code.
- Efficient execution times that do not significantly slow down overall simulation time.
- Minimal memory usage, including zero-copy usage when bringing data from simulation routines to visualization and analysis routines.
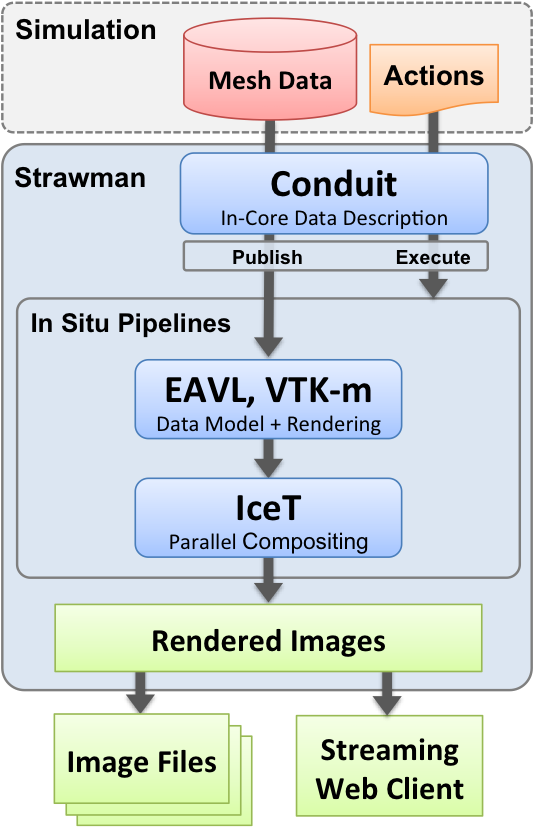
System Architecture¶
- The Strawman sytem architecture is composed of several components:
- Conduit: Conduit is used to describe and pass in-core mesh data and pipeline options from the simulation code to Strawman.
- In Situ Pipelines: Strawman contains a number of in situ pipelines that implement simple analysis, rendering, and I/O operations on the mesh data published to Strawman. At a high level, a pipeline is responsible for consuming the simulation data that is described using the Conduit Mesh Blueprint and performing a number of actions defined within Conduit Nodes, which create some form of output.
- Data Adapters: Simulation mesh data is described using Conduit’s Mesh Blueprint, which outlines a set of conventions to describe different types of mesh-based scientific data. Strawman provides internal Data Adaptors that convert Mesh Blueprint data into a more a more specific data model, such as VTK-m’s data model. Strawman will always zero-copy simulation data when possible. To simplify memory ownership semantics, the data provided to Strawman via Conduit Nodes is considered to be owned by the by the simulation.
- IceT: Strawman uses IceT for scalable distributed memory parallel image compositing.
- Embedded Web Server: Strawman can stream images rendered from a running simulation to a web browser using the Conduit Relay’s embedded web-server.
System Diagram¶
Pipelines¶
Strawman can be configured with one or more of the following pipelines. When multiple pipelines are built with Strawman, available pipelines can be selected at runtime. A pipeline has three main functions: consume simulation data, perfrom analysis (optional), and output data. Data describing the simulation mesh is sent to the pipeline within a Conduit Node which is formatted according to Conduit Blueprint. Once the data is in a compatible format, the pipeline can optionally perfrom some analysis operations, and then output the results. Currently, the VTK-m and EAVL pipelines output images to either the file system or to the web browser, and the HDF5 pipeline creates and HDF5 file.
VTK-m¶
VTK-m v1.0 is a header only library (future versions will exist as a static or shared library) that uses a data-parallel programming model. VTK-m was created from the merging of three efforts: DAX, EAVL, and PISTON. While VTK-m’s main focus is on scientific visualization, it can be used as a general purpose library for execution of supported architectures. It uses template-meta programming to provide flexible and performant execution, and VTK-m is currently under active development. The current version of Strawman uses the tagged 1.0 release that can be found at Kitware and the user guide can be found at m.vtk.org.
Supported operations:
- Structured volume rendering
- Ray tracing
Access to VTK-m filters are coming in a future release.
EAVL¶
EAVL is the Extreme-Scale Analysis and Visualization Library that was developed as a research project at Oak Ridge National Laboratory. EAVL’s focus was to develop a more flexible and efficient model for scientific data sets. EAVL uses a data-parallel programming model that abstracts away the underlying computer architecture, allowing algorithms developed in EAVL to be written once and executed on any supported architecture. Serial, OpenMP, and CUDA back-ends are supported in EAVL. EAVL is no longer under active development, and it efforts have been absorbed into VTK-m. The branch used by Strawman can be found on EAVL’s github page as well as the documentation. EAVL is no longer under active development, as the devopers efforts now go toward the VTK-m project.
Supported operations:
- Strucutured and unstructured volume rendering
- Ray tracing
- Rasterization (OSMesa)
- Limited filter support
Blueprint HDF5¶
This pipeline saves published mesh data to a set of hdf5 files that can be read by the VisIt Blueprint plugin (planned to be released with VisIt 2.13).
Empty¶
The empty pipeline contains all the boilerplate code needed to started implementing a custom pipeline and is meant to serve as a staring place for those that wish to create a pipeline from scratch.